Understanding Predictive Analytics
Data Collection and Preparation
A robust predictive model hinges on the quality and quantity of the data it's trained on. This involves meticulously gathering relevant information from various sources, ensuring data accuracy and consistency. Thorough data cleaning is crucial, addressing missing values, outliers, and inconsistencies. This process often involves transforming raw data into a format suitable for analysis, such as standardizing units and creating new variables.
Data preparation extends beyond simply cleaning the data. It also includes exploring the data to identify patterns and relationships. This exploratory data analysis (EDA) is essential to understanding the data's characteristics, potential biases, and the variables that may be most predictive of the desired outcome. Properly prepared data forms the bedrock of any successful predictive analysis.
Statistical Modeling Techniques
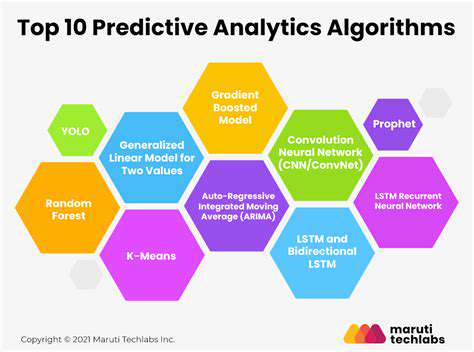
A wide array of statistical modeling techniques are available to build predictive models. Choosing the appropriate technique depends heavily on the type of data and the desired outcome. Linear regression, for example, is suitable for predicting continuous outcomes, while logistic regression is better suited for binary outcomes. Decision trees and random forests are powerful techniques for more complex relationships.
Understanding the strengths and limitations of each technique is vital for choosing the most effective approach. Careful consideration of model assumptions and potential biases is crucial. Evaluation metrics, such as accuracy, precision, recall, and F1-score, play a vital role in assessing the performance of different models and selecting the best one for the specific application.
Feature Engineering and Selection
Predictive models often benefit from carefully engineered features. Feature engineering involves creating new variables from existing ones, or transforming existing variables to better capture the relationships within the data. This can involve combining existing features, creating polynomial terms, or applying domain expertise to derive new insights. Feature engineering can significantly enhance model performance.
Selecting the most relevant features is equally important. Redundant or irrelevant features can negatively impact model performance. Feature selection techniques help identify and eliminate these features, leading to simpler and more efficient models. Choosing the right features can make the difference between a good and a great model.
Model Evaluation and Validation
Evaluating and validating predictive models is critical to ensure their reliability and generalizability. This involves splitting the data into training and testing sets to assess the model's performance on unseen data. Various metrics and techniques, such as cross-validation, are used to evaluate the model's accuracy and robustness. Careful evaluation is essential to avoid overfitting, where the model performs exceptionally well on the training data but poorly on new, unseen data.
Interpreting model results and understanding their implications is also crucial. This involves determining which factors are most influential in predicting the outcome and understanding the strengths and limitations of the model. Interpreting the model's predictions in the context of the business problem is essential.
Deployment and Monitoring
Successfully deploying a predictive model into a real-world application involves integrating it into existing systems and processes. This might involve developing APIs, integrating with databases, or creating user interfaces. Proper deployment ensures that the model's predictions are readily accessible and actionable.
Ongoing monitoring of the model's performance is essential. As new data becomes available, the model's accuracy and reliability can degrade. Regularly monitoring the model's performance and updating it as needed ensures its continued effectiveness. This is crucial for maintaining accuracy and relevance over time.
Deployment and Monitoring (Additional Section)
A crucial aspect of deploying a predictive model is ensuring its ongoing performance. This involves monitoring the model's accuracy and adjusting it as needed. Regular performance checks are vital to maintain the model's predictive power over time. This can be achieved through techniques like retraining the model periodically with new data to adapt to evolving patterns. This ongoing refinement and adjustments prevent the model from becoming obsolete or inaccurate, thus maintaining its reliability and predictive power.
Furthermore, monitoring the model's performance in a real-world environment is essential to identify potential issues or biases that might not be evident in the initial evaluation. Close observation of its performance in actual use helps uncover and address emerging problems.

Read more about Understanding Predictive Analytics


![Understanding Cryptocurrency: Beyond Bitcoin [Explained]](/static/images/25/2025-05/TheFutureofCryptocurrencies3ANavigatingtheChallengesandOpportunities.jpg)
![How to Automate Your Workflow with [Automation Tool]](/static/images/25/2025-05/OptimizingYourZapsforEfficiency.jpg)


![How to Prepare for a Coding Interview [Tips & Tricks]](/static/images/25/2025-05/Practice2CPractice2CPractice21.jpg)
Hot Recommendations
- Review: The New [Specific Brand] Smart Lock Is It Secure?
- Best Budget Studio Monitors for Music Production
- Top Flight Simulation Peripherals (Joysticks, Throttles, etc.)
- Top Portable Scanners for Document Management On the Go
- Reviewing the Latest Smart Air Purifiers for Your Home
- Best Portable Photo Printers for Travelers and Memory Keepers
- The Future of Personal Transportation Beyond Cars (Hyperloop, eVTOL)
- Top Network Monitoring Tools [Free & Paid Options]
- Understanding the Tech Behind mRNA Vaccines [A Look Inside]
- Guide to Choosing the Right Gaming Chair for Ergonomics