What is Federated Learning in AI?
Challenges in Federated Learning
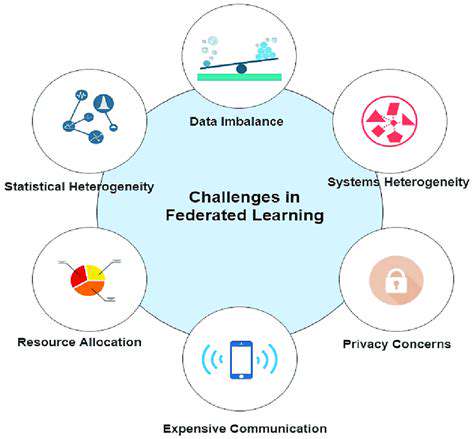
Data Heterogeneity
A significant hurdle in federated learning is the inherent variability in data characteristics across different participating devices. This heterogeneity, encompassing differences in data distribution, quality, and format, can significantly impact model performance. For example, a model trained on images of handwritten digits might perform poorly when applied to images of printed text due to the variations in the data distributions. Different devices might also have different levels of data labeling accuracy, further compounding the problem.
Communication Overhead
Federated learning algorithms rely heavily on communication between the central server and the participating devices. This communication, often wireless, can be susceptible to latency and bandwidth limitations. High communication overhead can lead to substantial delays in model updates and reduced efficiency, especially in scenarios with a large number of devices or limited network bandwidth. Furthermore, security concerns associated with transmitting sensitive data across networks also need to be addressed.
Privacy Concerns
Federated learning aims to train models without sharing raw data, but concerns about privacy remain. The central server may still gain insights into the data characteristics by observing model updates. Furthermore, the aggregation of model updates across devices can potentially reveal sensitive patterns or correlations within the data. Robust privacy-preserving techniques are crucial to mitigate these risks.
Model Accuracy and Generalization
Ensuring that federated learning models achieve comparable accuracy and generalization performance to models trained on centralized datasets is a significant challenge. The limited data available on individual devices can lead to overfitting and poor generalization to unseen data. Strategies to address this challenge often involve careful selection of model architectures, appropriate regularization techniques, and data augmentation methods.
Computational Resources
The computational resources available on participating devices can vary significantly. Some devices might possess powerful GPUs, while others may rely on limited CPUs. This disparity in computational capabilities can lead to uneven participation and potentially slow down the overall federated learning process. Moreover, the computational cost of training models on decentralized devices can be substantial.
Security and Robustness
Ensuring the security and robustness of the federated learning system is critical. Malicious participants or compromised devices can potentially inject noise or adversarial examples into the model updates, compromising the integrity of the learning process. Robust mechanisms to detect and mitigate these attacks are needed to build a trustable federated learning system. This includes secure communication protocols and mechanisms to validate model updates.
Scalability and Efficiency
As the number of participating devices increases, the scalability of federated learning becomes a critical concern. The system needs to efficiently manage the communication and computation demands. Efficient algorithms and optimized communication strategies are required to maintain performance as the scale of the system grows. Moreover, the system must be adaptable to different network topologies and device characteristics to ensure smooth operation.
Read more about What is Federated Learning in AI?


![Understanding Cryptocurrency: Beyond Bitcoin [Explained]](/static/images/25/2025-05/TheFutureofCryptocurrencies3ANavigatingtheChallengesandOpportunities.jpg)
![How to Automate Your Workflow with [Automation Tool]](/static/images/25/2025-05/OptimizingYourZapsforEfficiency.jpg)
![How to Use a Cybersecurity Kill Chain Model [Understanding Attacks]](/static/images/25/2025-05/Exploitation3ATakingAdvantageofVulnerabilities.jpg)

Hot Recommendations
- Review: The New [Specific Brand] Smart Lock Is It Secure?
- Best Budget Studio Monitors for Music Production
- Top Flight Simulation Peripherals (Joysticks, Throttles, etc.)
- Top Portable Scanners for Document Management On the Go
- Reviewing the Latest Smart Air Purifiers for Your Home
- Best Portable Photo Printers for Travelers and Memory Keepers
- The Future of Personal Transportation Beyond Cars (Hyperloop, eVTOL)
- Top Network Monitoring Tools [Free & Paid Options]
- Understanding the Tech Behind mRNA Vaccines [A Look Inside]
- Guide to Choosing the Right Gaming Chair for Ergonomics